En esta entrada vamos a iniciarnos en el mundillo del PHP, aprendiendo a conectar los datos de una página web con una base de datos MySQL. En mi caso, partiré de que ya tengo creada la base de datos con sus tablas y sus claves, así como instalado el servidor web del XAMPP y todo bien configurado con host virtuales para poder acceder desde mi navegador a mis páginas HTML sin problemas.
Empezamos, pues, con la base de datos:
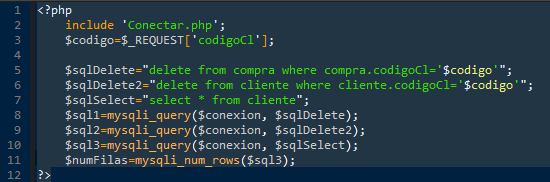
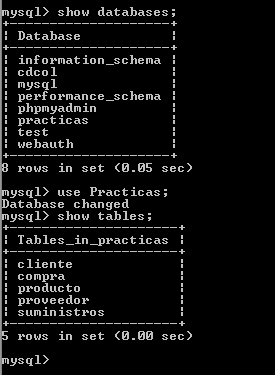
Podría hacerlo de forma gráfica, pero por comandos puedo acceder más rápido a la información de las tablas en caso de que algo haya salido mal. En la imagen anterior he mirado todas las bases de datos que tengo, y me decidiré a usar "Practicas", donde tengo todas las tablas. El escenario es muy sencillo: en una tienda de informática, tenemos clientes, tenemos productos, y proveedores. La tabla "compra" nos vinculará los clientes con los productos, registrando lo que han comprado. La tabla suministros, en cambio, nos dará la información acerca de los productos que nos hayan suministrado los proveedores.
Hasta aquí todo bien, pero ahora vamos a pasar al código. Lo primero que tenemos que hacer es un formulario sencillito en HTML para poder recoger datos de nuestros clientes, y estos datos posteriormente, mediante el uso de ficheros PHP, los registraremos en nuestra base de datos.
Empezamos, pues, con nuestra página web:
Primero generaremos un fichero de texto con extensión HTML, asegurándonos de que tiene la codificación "UTF-8" (para evitar que en lugar de tildes, aparezcan símbolos extraños al visualizar la página). Esto podemos hacerlo de muchas formas, pero yo prefiero esta, que es más rápida:
Reiterar que, lo importante de esto, es la codificación de caracteres. Ahora utilizaremos la herramienta de Aptana para editar y crear nuestra propia página web, que consistirá en un formulario sencillo para registrar clientes de nuestra tienda de informática:
Esta será, básicamente, la carcasa de nuestra página web. Tenemos que darnos cuenta de la etiqueta "DOCTYPE", que nos indicará qué versión de HTML utilizaremos (en este caso, supone que es HTML5), también tenemos la etiqueta "head" con la codificación, el título de la página, y un enlace a hojas de estilo CSS que no tendrá, de momento, un archivo asociado. Más adelante, cuando tengamos el formulario hecho, insertaremos en el atributo "href" un fichero de CSS para poder trabajar con colorines y tal.
Luego, debajo, tenemos la etiqueta "body" con el formulario, cuyo nombre será formulario, método post y el action ejecutará un fichero PHP cuando enviemos los datos, por ahora no tenemos creado ese fichero, así que lo dejamos vacío. Ya iremos rellenando estos atributos.
Ahora tenemos que crear el formulario en sí, y para esto, es suficiente con colocar etiquetas de "input". Pero antes, ¿qué datos necesitamos del cliente? Pues eso lo tenemos en nuestra base de datos MySQL:
La tabla de los clientes tendrá un código, que se auto incrementará con cada registro o tupla que insertemos en ella. También tendrán un nombre, unos apellidos, una dirección y un teléfono. Entonces, teniendo esto en cuenta, creamos un campo para cada columna de nuestra tabla ignorando el código del cliente, que se incrementa solo (reitero):
Creamos un título de nivel tres, y varios párrafos donde tendremos un bloque "span" y un "input" para insertar nuestros datos, además del botón. Toda esa retahíla de código, que tampoco es muy complicada, se traduce en lo siguiente:
Podemos ver el título de nivel tres en negrita, los bloques "span" antes de los "input", y los tamaños y valores que hemos asignado por defecto en las etiquetas. El evento "onclick", nos dice, que cuando pinchemos con el ratón sobre "Inserte su nombre" (o cualquier otras etiqueta "input"), su valor será nulo, es decir, la cajita de texto se vaciará. Y el atributo "name", nos servirá más adelante en el PHP para identificar cada etiqueta y recoger sus valores.
Sin embargo, ese formulario es muy soso y triste, no nos vendría mal añadirle un archivo CSS para darle vidilla:
Especificando que la cabecera de nivel tres tenga ese color en su texto, las etiquetas "input" tengan el color de su texto negro, en negrita, cursiva y en fuente Times New Roman. Y finalmente, creamos un estilo para las etiquetas "div" de nuestro documento (solo utilizaremos una): con posición relativa, margen y padding inexistentes, ancho a 500 pixels, y alto automático, el borde será de tipo groove, y tanto el fondo como el propio borde serán de color dorado. Si ahora modificamos el fichero HTML tal que:
Insertamos en el "href" del "link" nuestros estilos, y metemos dentro del formulario un contenedor "div", teniendo, finalmente, lo siguiente:
Ahora está mucho más bonito, ¿a qué sí? =)
Pues para eso tenemos el CSS. Ahora bien, el siguiente paso será entrar ya en el PHP. Lo primero que tenemos que hacer es conectar con nuestra base de datos como si fuésemos un usuario de la misma. Yo entraré con permisos de administrador, aunque siempre podemos crear usuarios en MySQL y otorgarles permisos. Pero bueno, en lo que a conectar con la base de datos "Practicas" se refiere, tendremos que crear un fichero PHP que nos haga esta función:
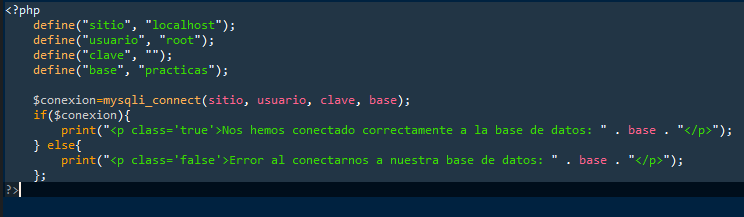
El concepto es sencillo, y evidentemente, esto será un fichero de pruebas que luego tendremos que editar, digamos que es una versión beta. Definimos constantes en base a los parámetros que nos pide la función "mysqli_connect", que será el lugar donde está nuestra base de datos (hay que recordar que, si tenemos un dominio y nuestro servidor es accesible desde internet, tendremos que utilizar nuestra dirección IP y tener conexión para poder conectar, en nuestro caso, al estar en local, será localhost), nuestro usuario, su clave que no la pondré aquí por razones de seguridad, y la base de datos.
Y la función para conectar, la pasamos a una variable que contendrá información. Si la conexión ha sido un éxito generaremos un fichero con una clase llamada "true" (a la que aplicaremos un estilo de background verde y color blanco), y en caso contrario sacaremos otro párrafo que nos dirá acerca del error. Esto se debe a que si la función va bien, la variable nos devolverá un booleano "true", sino, será un "false". Y los puntos del "print", nos concatenan cadenas de caracteres.
Cabe destacar, además, que un fichero PHP puede incluir etiquetas HTML, y puede ser perfectamente, una página web. Podemos, encima del código PHP, escribir un DOCTYPE, un head, y vincular nuestro fichero css al archivo PHP, que lo que hará el navegador será ejecutar este código en base a la conexión y sacar una web con un párrafo u otro. Es muy simple el concepto.
Si la conexión ha ido bien y hemos creado nuestros estilos en CSS, tendremos lo siguiente:
Podemos ver cómo la constante "base" en el print se sustituye por la base de datos que tenemos en MySQL. Y viendo lo extenso que se ha vuelto esto, hasta aquí es todo por el momento. En una futura entrada crearemos más ficheros PHP que gestionen los datos que hemos insertado en el formulario.
¡Nos vemos!